Intention généralecomprendre le principe de numérisation des images
Pour une meilleure compréhension de ce module, nous vous conseillons de parcourir d'abord le module « Comprendre le traitement de l'information numérique ».
Les images produites par des appareils électroniques sont fatalement des images numériques. Comment cette numérisation est-elle possible, c'est ce que nous allons essayer de comprendre dans ce module. Une connaissance élémentaire des principes généraux de cette numérisation nous permettra d'améliorer encore nos performances et nos productions.
1. Images mosaïques
Mise en situation
Vous connaissez sans doute le principe de la mosaïque. De petits morceaux de pierre, d'émail, de
verre, de céramique sont assemblés pour former une image.
Le Jugement de Pâris, mosaïque de sol d'Antioche, 1er siècle, musée du Louvre
L'image ci-dessus est comme une peinture. Qu'est-ce qui fait que nous avons cette impression ?
C'est parce que nous la regardons d'assez loin que nous avons cette impression. Une vue de très près nous ferait percevoir les choses différemment.
Par exemple, regardons de plus près certaines images réalisées suivant le même principe.
Source : http://www2.fsg.ulaval.ca/
Source : http://www.la-tesselle-dor.com/
Est-ce aussi simple de se représenter ce dont il s'agit ?
Pourquoi ? Discutons-en à la page suivante.
1. Images mosaïques
Réflexions
Le principe de la mosaïque, c'est de reproduire une image à partir de multiples éléments colorés. Parfois, ces morceaux sont de forme régulière, parfois non, mais c'est relativement peu important puisque l'image est censée être vue à une certaine distance.
Chacune des images proposées nous permet d'en deviner les détails : de petits morceaux de pierre (ou de verre) colorés ou des disques également colorés.
Mais, si nous regardons ces mêmes images de plus loin (voire de très loin), nous ne distinguons plus ces détails.
En optique, on parle de pouvoir séparateur de l'œil. Le pouvoir séparateur de l'œil est la faculté qu'a cet œil de discerner deux points distincts avant d'en voir un seul. On considère que, pour un individu moyen, il est de 1 mm si on se trouve à une distance de 3 mètres. Cela signifie encore que si nous arrivons à distinguer deux points sur la surface de la Lune, ils sont séparés d'au moins 100 km.
Grâce à ces chiffres, pouvez-vous estimer de quel ordre de grandeur est la distance terre-lune ?
Pouvoir séparateur :
1 mm -> 3 m 100 km = 100.000.000 mm 100.000.000 mm -> 300.000.000 m = 300.000 km
La distance terre-lune est en réalité de 384.000 km.
1. Images mosaïques
Activités
Peindre d'après les chiffres
Rappelez-vous votre enfance et les « livres à colorier ». Qui parmi vous ne s'est jamais lancé dans une telle activité ? Colorier chaque surface numérotée permettait de réaliser de véritables chefs-d'œuvre. Retour en enfance…
Objectif
transformer une suite de nombres en image
À cause du pouvoir séparateur limité de l’œil humain, nous percevons une image construite au moyen d'un très grand nombre d'éléments distincts et minuscules dans sa globalité.
Ce constat est exploité par les systèmes informatiques qui commandent des dispositifs (imprimante, moniteur…) capables de produire de tels éléments (point lumineux sur un écran, point d'encre sur une feuille de papier…).
Le fait que ces éléments puissent être dissociés permet aux systèmes informatiques de traiter les images. Chacun des éléments minuscules est appelé pixel (de « picture element »).
Dans sa représentation, une image peut être considérée comme une matrice rectangulaire de pixels. C'est aussi pourquoi on parle d'image matricielle.
Image numérique
L'association d'un code de couleur (valeur numérique) à chaque pixel transforme l'image en image numérique.
Si la plupart des nombres qui composent l'image numérique correspondent aux couleurs des différents pixels, certains nombres représentent des informations utiles à sa reconstitution en sortie, notamment les dimensions de l'image (nombre de pixels en largeur et en hauteur).
1. Images mosaïques
Exercices
Vous pouvez obtenir le corrigé des exercices auprès de votre coach.
Vous le savez désormais, une image est codée par le système en une suite de nombres entiers suivant une convention de codage.
Cette convention contient au moins des informations sur :
les dimensions de l'image (largeur et hauteur en nombre de pixels) ;
la couleur de chacun des pixels de l'image.
La position de ces informations dans la suite peut varier selon la convention choisie. Il est donc indispensable de connaître cette convention pour espérer décoder une image.
Dans cet exercice et les suivants, la convention vous sera précisée.
L'image qui précède a été codée suivant la convention :
un nombre de deux chiffres pour la largeur de l’image en nombre de cases,
un nombre de deux chiffres pour la hauteur de l’image en nombre de cases,
un nombre d'un seul chiffre pour la couleur de chacune des cases.
À quel code correspond cette image ? Choisissez la bonne proposition :
À ces suite de nombres entiers correspondent des images qu'il vous faut reconstituer. Coloriez les cases qui composent la grille ci-dessous. Pour cela, sélectionnez d'abord une couleur dans la palette et cliquez ensuite sur la case que vous souhaitez mettre en couleur.
Suite 1 : 89888899988889888888988888899998888898888889999888889888888889888888889998
Suite 2 : 89888888888444444884222248844442488422224884244448842222488444444888888888
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
°
Convention de codage :
un nombre d'un seul chiffre pour la largeur de l’image en nombre de cases,
un nombre d'un seul chiffre pour la hauteur de l’image en nombre de cases,
un nombre d'un seul chiffre pour la couleur de chacune des cases.
Albert est un daltonien dichromate : il a tendance à confondre le vert et le rouge qu'il voit tous deux jaunes (un jaune plus clair et un autre plus foncé).
Sachant cela, quel sera le codage obtenu par Albert s'il regarde en même temps l'image et le code des couleurs proposés ci-dessous ?
un nombre d'un seul chiffre pour la largeur de l’image en nombre de cases,
un nombre d'un seul chiffre pour la hauteur de l’image en nombre de cases,
un nombre d'un seul chiffre pour la couleur de chacune des cases.
Aidez-vous de la légende !
Mais avant de vous lancer dans l'aventure, posez-vous la question de savoir s'il n'existe pas une manière « économique » (machinale) d'écrire le code. Si vous ne voyez pas, lisez l'indice fourni ci-dessous.
Observez bien le dessin. Il existe une manière "économique" d'écrire le code. D'abord, lorsque vous aurez codé la moitié d'une ligne, ensuite, lorque vous aurez codé la moitié de la figure…
Vous souhaitez en apprendre plus sur le pixel
… Vous trouverez ici des informations vous permettant de compléter vos connaissances.
Libérez l'artiste qui est en vous en créant des photos mosaïques à partir de vos propres photos grâce à un logiciel téléchargeable gratuitement et facile d'utilisation.
2. Le poids des images
Intention généraleconnaitre les standards de codification des images (modèles associés) et les liens entre les différents paramètres d'une image (définition, résolution, profondeur, taille en cm et poids en octets)
Nous avons joué à inventer des codages pour les images. À présent découvrons la vraie façon dont certaines images sont codées avant de pouvoir être traitées.
Pour que les systèmes puissent communiquer entre eux, il a évidemment fallu réfléchir à des standards de codification des couleurs. Différents modèles existent pour les décrire et donc les coder.
Nous découvrirons que, selon les systèmes de codage utilisés, les images sont plus ou moins « lourdes ». Comme elles sont numériques, leur poids se mesure en octets (o), Kilo-octets (Ko), Méga-octets (Mo)…
2. Le poids des images
Mise en situation
Commençons par une bizarrerie de vocabulaire.
Une image numérique se compose d'une suite de bits. On mesure donc logiquement son poids en octets. On parle de poids car on dit souvent qu'une image est « lourde », par exemple, lorsqu'on souhaite l'envoyer en attachement d'un courriel.
Par ailleurs, tout système informatique enregistre une image sous forme de fichier. Et en matière de fichier, vous le savez, on parle de taille et non plus de poids.
Le poids d'une image, c'est donc aussi la taille du fichier qui la contient. Qu'on se le dise ! Et surtout, qu'on soit attentif à cette nuance de vocabulaire.
Observez les paires d'images qui suivent. Dans chaque cas, le poids de l'image A est inférieur au poids de l'image B.
Davantage de couleurs sont utilisées dans l'image de droite.
Série 3
Image A
Image B
Comment expliquer que dans ce troisième cas, on ne constate plus de différences ?
Passons aux explications.
2. Le poids des images
Réflexions
Le poids
Le poids d'une image numérique équivaut à la taille du fichier qui lui correspond. Elle s'exprime donc le plus souvent en Ko ou en Mo.
Quel est le poids d'une image produite par un scanneur ou un appareil photo numérique ?
Capteur CCD
Chaque cellule du capteur d'un appareil photo numérique génère un pixel. Ainsi, un appareil photo numérique dont le capteur comporte huit millions de cellules peut prendre une photo composée de huit millions de pixels (huit mégapixels). Cependant, il est possible, en faisant des réglages de l'appareil, de n'utiliser qu'une partie des cellules disponibles.
Scanneur
Un scanneur fonctionne de manière un peu différente, puisqu'il pratique par balayage du support à scanner. Les cellules sont alignées et la captation est réalisée progressivement pendant le balayage.
Dans l'un comme dans l'autre cas, plus le nombre de pixels est élevé, plus le poids des images produites est important. Logique ! À chaque pixel est associé une couleur, et chaque couleur est codée numériquement.
Le nombre de pixels est-il le seul élément qui intervient dans le poids d'une image ?
L'image numérique est une longue suite de nombres. La longueur de cette suite ne dépend pas que du nombre de pixels. Elle dépend également du nombre de chiffres utilisés pour le codage des couleurs.
La profondeur
Plus l'image contient de couleurs différentes, plus le nombre de chiffres nécessaires pour coder chaque couleur est élevé. Le choix du nombre de chiffres binaires utilisé par un système informatique pour coder les couleurs va donc déterminer le nombre de couleurs pouvant être codées.
Le nombre de bits associé à chaque couleur est appelé profondeur de l'image.
Palette de 256 couleurs
Les couleurs ont longtemps été codées sur huit bits, c'est-à-dire sur un octet. Ce sont essentiellement les limites de capacité de stockage des supports qui en ont été la raison. Par ailleurs, des images lourdes prenaient du temps à être transférées et les vitesses de transfert n'étaient pas aussi élevées qu'elles le sont actuellement.
Vous le savez désormais, une image dont les couleurs sont codées sur un octet peut contenir jusqu'à 256 couleurs différentes.
On utilise souvent le mot « palette » pour désigner l'ensemble de ces couleurs en référence à la palette du peintre. Juste une petite différence, le peintre peut mélanger les couleurs. Un système informatique utilise les 256 couleurs de la palette, telles qu'elles.
Image A : codage des couleurs sur huit bits
Observons à nouveau la photo du balcon. Un système informatique l'a codée en utilisant huit bits pour identifier la couleur de chaque pixel.
On doit admettre que la qualité de l'image n'est pas exceptionnelle. Les transitions entre les couleurs sont assez brutales.
Image B : codage des couleurs sur vingt-quatre bits
Le même système a cette fois utilisé vingt-quatre bits pour l'image B.
Nous constatons que l'image est plus nette. Quelle en est la raison ?
Beaucoup plus de couleurs sont utilisées dans l'image B et donc, les nuances sont plus fines. Si on code chaque couleur sur un octet, on ne peut disposer que de 256 couleurs différentes pour reproduire l'image. Si on code chaque couleur sur trois octets, on dispose de plus de 16 millions de couleurs (256 x 256 x 256). Le dégradé des couleurs est donc beaucoup plus fin et l'image paraît plus nette.
Pourquoi avoir choisi de coder les couleurs sur 24 bits et non sur 16 ou 10 ou 20…? En avez-vous une idée ?
L’œil humain perçoit la lumière grâce à des cônes sensibles davantage au rouge, au vert ou au bleu.
Cônes et bâtonnets
C'est la raison pour laquelle les couleurs que nous percevons sont un mélange de ces trois couleurs fondamentales qu'il ne faut d'ailleurs pas confondre avec les couleurs fondamentales en peinture. Nous verrons plus loin pourquoi.
L'idée du codage des couleurs sur 24 bits (trois octets) a été d'utiliser un octet pour coder, non plus 256 couleurs différentes, mais 256 intensités différentes de chacune de trois couleurs de base.
Une couleur turquoise et ses trois composantes
Une couleur est donc définie comme un mélange en proportions diverses de rouge, de vert et de bleu.
Pour toutes ces raisons, les images codées en 24 bits ou trois octets sont dites images en vraies couleurs.
Interrogeons-nous maintenant sur l'évolution du poids des images avec la profondeur.
De quel facteur va augmenter le poids d'une image si on code ses couleurs en 24 bits au lieu de 8 bits ?
Comme la couleur de chaque pixel est représentée par un nombre binaire trois fois plus grand, la longueur de la suite de nombres est multipliée par trois.
Ce qui doit nous étonner un peu, c'est qu'en augmentant d'un facteur trois le poids des images, on puisse augmenter le nombre de couleurs disponibles de 256 à plusieurs millions.
Observons maintenant les deux images qui suivent.
Image A
Image B
Elles semblent pareilles. Pourtant, les couleurs de l'une sont codées sur 8 bits et celles de l'autre sur 24 bits. Comment cela s'explique-t-il ?
Ces deux images contiennent en fait peu de couleurs différentes. Qu'on utilise une palette de 256 couleurs ou de plus de 16 millions de couleurs pour son codage n'a donc pas beaucoup d'impact sur le résultat.
En revanche, cela en a sur le poids des deux images puisque la deuxième pèse trois fois plus lourd que la première.
Les activités qui suivent vont vous permettre de mesurer le poids des images en fonction des choix de codage que vous pourriez faire.
Notez déjà que vos appareils photos numériques compressent vos photos avant de les stocker sur leur support. Mais cela, c'est une autre histoire dont nous reparlerons dans un des chapitres suivants.
La résolution
Les images ont besoin de supports pour pouvoir être admirées.
Pouvez-vous en citer quelques-uns ?
On peut les classer en deux grandes catégories. Voyez-vous lesquelles ?
Il y a les écrans LCD (ordinateurs, smartphones, iPads…) qui sont éclairés (apport direct de lumière) et les supports de type feuilles de papier, écran de projection, murs blancs… qui réfléchissent la lumière qu'ils reçoivent (qu'elle soit naturelle ou artificielle).
La qualité d'une image est liée à la densité des points (pixels) sur le support. Plus cette densité est élevée, plus l'image est nette. Et l'œil humain se satisfait d'une certaine densité, étant donné son pouvoir séparateur.
Cela dit, une image étant composée d'un nombre déterminé de pixels, plus la densité de ces pixels est élevée sur le support, et plus l'image sera petite. Vous verrez, dans les activités, en quoi cette densité, aussi appelée résolution, est variable d'un support à l'autre et quelles en sont les conséquences.
2. Le poids des images
Activités
Prendre du poids
Comment estimer le poids d'une image et donc la taille du fichier qui la contient ? Et que faire si ce poids est trop élevé ?
Il existe différentes manières de définir la couleur et surtout de la modéliser. Au cours de cette activité, nous allons examiner les modèles qui nous sont proposés par les programmes de traitement d'images.
Objectif distinguer les modèles de couleurs et les exploiter en connaissance de cause
La résolution concerne la densité des pixels et est donc liée au dispositif de reproduction des informations en sortie (écran, imprimante, projecteur vidéo...). Elle peut aussi être un paramètre de l'image. Quelle est son utilité ?
Objectif exploiter efficacement les relations entre taille de l'image en pixels, taille en centimètres, résolution du support et résolution de l'image
Visuellement parlant, une image matricielle est une matrice rectangulaire de pixels. À chaque pixel est attribué une couleur choisie parmi les N couleurs disponibles. Le nombre de couleurs disponibles dépend de la profondeur de l’image qui est le nombre de bits utilisés par le système pour la coder (quatre bits, huit bits, 24 bits…).
Une image dont la profondeur est de 24 bits est dite image en vraies couleurs. Une image dont la profondeur est de huit bits ne contient que 256 couleurs. Si les 256 couleurs de l'image correspondent à des couleurs dont les valeurs des trois composantes rouge, verte et bleue sont identiques, on parle d'image en 256 niveaux de gris.
Une image numérique est essentiellement composée de la suite des codes de couleurs de chacun de ses pixels, précédée de diverses informations telles : la profondeur de l’image, la palette de couleurs (si on ne travaille pas en vraies couleurs)…
Le poids d'une image s'exprime en octets (Ko ou Mo) et est dépendant du produit de trois nombres entiers : le nombre de pixels en largeur, le nombre de pixels en hauteur et le nombre d'octets qui correspond à la profondeur du codage.
Un format est dit ouvert si la manière dont il structure les informations est publique et donc exploitable.
Le format BMP est un format ouvert qui permet de coder les images matricielles.
Les couleurs
Il existe différents modèles de couleurs. Les trois modèles les plus utiles sont :
le modèle RVB, un modèle de synthèse additive qui correspond bien à la lumière diffusée par les écrans ;
le modèle CMJN, un modèle de synthèse soustractive qui correspond davantage à la lumière renvoyée par une image imprimée ;
le modèle TSL qui est tout simplement mieux adapté aux perceptions des êtres humains.
Les couleurs du modèle RVB sont le rouge, le vert et le bleu. Celles du modèle CMJN sont le cyan, le magenta et le jaune auxquelles on ajoute le noir, difficile et surtout coûteux à obtenir à partir des trois autres. Dans le modèle TSL, il n'est pas question de mélange de couleurs, mais de teinte, de saturation et de luminance.
Résolution et taille des images
La résolution d'un écran traduit la densité de pixels affichés à l'écran.
La résolution d'une imprimante traduit la densité de points qu'elle imprime.
La résolution d'un scanneur traduit la densité de captures qu'il effectue.
Les résolutions s'expriment en points par pouce (dot per inch) : ppp (dpi).
La résolution d'un écran normal tourne aux alentours des 72 dpi, celle d'une imprimante peut varier de 600 à 2.400 dpi, voire plus. Celle d'un scanneur est généralement de 1.200 dpi.
Les dimensions d'une image (en cm), sur un écran ou sur un support papier, dépendent de sa définition (nombre de pixels en largeur et en hauteur) et de la résolution du dispositif (d'affichage, d'impression).
2. Le poids des images
Exercices
Vous pouvez obtenir le corrigé des exercices auprès de votre coach.
Pour dessiner le drapeau belge, nous créons une image de 600 x 200 pixels. Découpons mentalement et verticalement ce rectangle en trois. Ensuite, remplissons chaque rectangle des couleurs du drapeau belge. Si cette image est enregistrée au format BMP et en 256 couleurs, quel sera le poids approximatif du fichier obtenu ?
Un fichier image au format BMP correspondant à une image en niveaux de gris est destinée à servir de fond d'écran (définition 1024 x 768 pixels). Quel est son poids approximatif ?
On décide de scanner une image de 4 cm x 4 cm à 150 ppp. Quel sera le poids approximatif du fichier image obtenu ? Quel poids aura-t-il si on scanne plutôt l'image à 300 ppp ?
Une image de 13 cm x 9,75 cm a été scannée à 150 ppp.
Quelle sera sa définition (dimensions en pixels) ?
À quelle résolution aurait-il fallu la scanner pour que sa définition corresponde à celle du moniteur, soit 1024 x 768, afin qu'elle puisse être directement utilisée comme fond d'écran ?
On dispose d'une image de 1280 x 800 pixels au format BMP, codée en « vraies couleurs ». On veut la transformer en niveaux de gris. Quels seront les poids de départ et d'arrivée du fichier correspondant à l'image ?
Ce second lien aborde la notion de modèle colorimétrique et vous fera découvrir, entre autres, le modèle RVB et le modèle TSL (qui correspond mieux à la perception que l'être humain a de la couleur).
3. Retouches et redimensionnements
Intention généraleidentifier les fonctionnalités de retouche et de redimensionnement des images et les utiliser à bon escient
Il ne suffit pas de capturer une image pour qu'elle soit directement utilisable. Il se peut que sa taille soit trop élevée.
Dans un texte, une présentation, une feuille de calcul… il est souvent possible et très commode de redimensionner dynamiquement (à la main) les images. Pourtant, vu le poids de ces images, c'est rarement une bonne solution. Que faire dès lors ?
Il se peut que l'image soit de qualité douteuse (yeux rouges, craquelures sur une vieille photo scannée…) ou qu'elle doive satisfaire à un critère (photo de passeport sur fond blanc)… Dans ce cas, il est nécessaire de comprendre les principes liés aux manipulations effectuées sur les images. On s'intéressera aussi aux conséquences en termes de qualité et de poids.
Avant
Après
Dans ce chapitre, vous allez découvrir les joies de la création, de la retouche et du redimensionnement des images.
3. Retouches et redimensionnements
Mise en situation
Retoucher
Si vous prenez régulièrement des photos en utilisant un flash électronique, vous connaissez sans doute la problématique des yeux rouges.
Comment corriger cela?
De même, celles et ceux qui portent des lentilles de contact savent qu'il en existe de différentes couleurs et qu'un changement de couleur des yeux peut engendrer des transformations étonnantes du visage.
Dans les activités qui suivent, nous allons apprendre à retoucher des images. Dès lors, vous pourrez vous amuser à changer plusieurs fois la couleur de vos yeux sur une de vos photos et découvrir ainsi vos multiples visages.
Recadrer, redimensionner
Quelquefois, on voudrait recadrer une image pour supprimer des zones qui ne sont pas nécessaires ou utiles. On peut avoir envie d'isoler, puis d'agrandir une zone spécifique de l'image. Est-ce toujours possible ?
Les agrandissements ont des conséquences et c'est rarement au bénéfice de la qualité de l'image.
On a recadré l'image ci-dessus en se limitant à la zone indiquée par un rectangle rouge. Ensuite, on l'a agrandie en utilisant deux techniques. Voyez plutôt.
Sans lissage
Avec lissage
Vous pouvez constater qu'en fonction des choix des paramètres effectués, les résultats peuvent être assez différents et pas toujours très satisfaisants.
Alors, quels sont les bons choix ? Quelles sont les bonnes pratiques ?
À nouveau, nous allons essayer d'y voir plus clair.
3. Retouches et redimensionnements
Réflexions
Les images matricielles peuvent représenter des choses très différentes : la photographie d'un paysage ou d'un portrait, l'icône d'un objet, une image de fond (unie ou avec un dégradé de couleurs) ou encore une affiche contenant un mot, une page contenant un texte ou un mur rempli de hiéroglyphes.
Pourtant, elles ont une caractéristique commune, elles sont constituées de pixels qui sont, chacun, d'une couleur bien définie.
Retoucher
Définir une image comme un ensemble de pixels nous aide à percevoir très simplement la retouche d'une image, quelle qu'elle soit, comme une modification de la couleur d'une partie de ses pixels (ou plus rarement, de tous ses pixels).
Dans les activités qui suivent, nous allons découvrir que les très nombreuses fonctionnalités des logiciels de dessin matriciel et de retouche d'image se ramènent toutes à ce principe simple.
Eh oui ! Qu'il s'agisse de gommer certains « défauts », de changer la couleur de l'arrière-plan d'une photo de passeport, de rendre une photo plus contrastée ou encore d'y intégrer une partie provenant d'une autre image, toutes ces manipulations qui peuvent paraître complexes consistent uniquement en des modifications de la couleur d'un nombre plus ou moins important de pixels.
Comprendre comment cela est possible va vous aider à travailler, retravailler, retoucher vos images avec davantage d'efficacité.
Redimensionner
Autre préoccupation : vous souhaitez modifier la taille d'une image (la réduire, l'agrandir, en extraire une partie).
Pour un système informatique, en quoi peuvent bien consister l'agrandissement et le rétrécissement d'une image ?
Il n'y a pas de mystère. Agrandir une image matricielle, c'est générer de nouveaux pixels. La rétrécir, c'est en supprimer.
Vous allez découvrir, au travers des activités qui suivent, comment cette génération et cette suppression ont lieu et quelles en sont les conséquences sur la qualité de l'image.
3. Retouches et redimensionnements
Activités
Dessine-moi un mouton
La création d'une image matricielle ou la retouche d'une photo mettent en œuvre des principes assez simples et pourtant mal connus.
Objectif exploiter les outils de création/retouche les plus courants
Retoucher un dessin, une image, c'est souvent une question de détail. Utiliser différentes « couches » peut s'avérer intéressant si on veut travailler proprement.
Objectif faire usage des calques dans un souci de propreté du travail de retouche
Grandir ou rétrécir…, pas toujours sans conséquences. Dans cette activité, vous allez le constater en même temps que vous découvrirez différentes techniques de redimensionnement.
Objectif
maîtriser les effets des techniques de redimensionnement (agrandissement ou réduction)
Toutes les fonctionnalités d'un logiciel de dessin matriciel consistent à modifier la couleur d'un groupe de pixels préalablement sélectionnés.
La sélection s'effectue grâce à différents outils, soit manuellement (outil rectangle), soit de manière semi-automatique (baguette magique) ou complètement automatique (outil remplissage).
Génération ou suppression de pixels
Pour agrandir ou rétrécir une image bitmap, les programmes de retouche d'images génèrent de nouveaux pixels ou en suppriment en utilisant une ou plusieurs méthodes au choix de l'utilisateur.
Quand le choix est possible, on détermine la méthode en fonction du type d'image et de l'effet souhaité.
L'agrandissement/le rétrécissement d'une image provoque un gain/une perte de poids et, dans les deux cas, une perte de qualité de celle-ci.
3. Retouches et redimensionnements
Exercices
Vous pouvez obtenir le corrigé des exercices auprès de votre coach.
Le terme tuning provient du verbe anglais « to tune » qui signifie accorder le réglage d'un moteur, entre autres.
Le tuning consiste, généralement, en l'installation d'accessoires intérieurs, extérieurs (éléments de carrosserie), de pièces mécaniques (suspensions) ou électroniques (systèmes multimédia).
Vous aussi, entrez dans le monde du tuning en modifiant la teinte de votre voiture. Pas la peine d'en faire des tonnes, quelques clics suffisent…
Attention, les effets d'ombre et de lumière doivent subsister. L'usage de l'outil de remplissage est donc déconseillé !
Désormais, plus rien ne devrait vous empêcher de modifier (à volonté) la couleur d'un élément dans une image. Ou plutôt presque rien…
Une fois encore, vous devez tuner votre voiture. Facile ? Pas si évident.
Plus question ici de n'en faire qu'à sa tête, il vous faut diminuer la valeur de la teinte de 70 unité exactement (valeur = -70) pour obtenir la couleur souhaitée. Par ailleurs, la couleur du fond ne peut changer !
La convention de Schengen est un accord qui stipule l'ouverture des frontières entre les différents pays d'Europe signataires. Le territoire créé par cette convention est appelé « espace Schengen ». Cependant, tous les pays en faisant partie n'y ont pas adhéré au même moment.
D'abord, téléchargez la carte d'Europe ci-dessous.
Ensuite, coloriez-la en fonction des dates d'adhésion et en utilisant les couleurs dont nous vous donnons les valeurs.
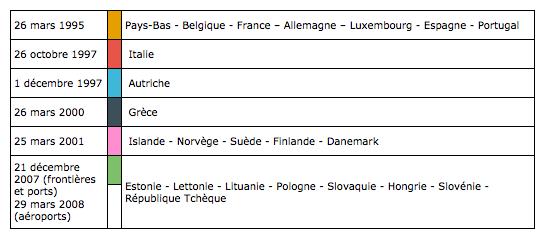
26 mars 1995 (R=230 V=159 B=0) : les Pays-Bas, la Belgique, la France, l’Allemagne, le Luxembourg, l'Espagne et le Portugal
26 octobre 1997 (R=232 V=84 B=71) : l'Italie
1 décembre 1997 (R=63 V=183 B=217) : l'Autriche
26 mars 2000 (R=60 V=80 B=90) : la Grèce
25 mars 2001 (R=255 V=142 B=209) : l'Islande, la Norvège, la Suède, la Finlande et le Danemark
21 décembre 2007 (frontières et ports) et 29 mars 2008 (aéroports) (R=126 V=192 B=105) : l’Estonie, la Lettonie, la Lituanie, la Pologne, la Slovaquie, la Hongrie, la Slovénie et la République Tchèque
Il s'agira, par la suite, de corriger les petites imperfections en usant de l'outil d'agrandissement, des pinceaux, gommes dont vous choisirez soigneusement les tailles afin de travailler proprement.
Puis, comme l'espace Schengen ouvre les frontières, il faudra les faire disparaître.
Enregistrez ensuite le fichier dans le format PNG.
Vous pouvez télécharger ci-dessous une légende reprenant les dates d'application de l'accord Schengen. Ajoutez-la sur la carte de l'exercice précédent et redimensionnez-la de manière à ce qu'elle reste lisible et qu'elle ne cache aucun des pays de l'espace Schengen.
Enregistrez l'image dans le format propriétaire du logiciel, ce qui vous permettra de retrouver les calques si vous voulez retravailler l'image. Puis, enregistrez-la au format PNG.
En grand romantique que vous êtes, vous vous lancez dans la création d'un pêle-mêle pour déclarer votre flamme.
Aucune consigne précise pour réaliser cet exercice, si ce n'est de respecter les proportions entre les différentes images et leur position et leur superposition. Soyez également attentif au remplissage de vos calques.
Observez bien l'aperçu ci-dessous avant de vous lancer.
Ne perdez pas la bonne habitude d'enregistrer l'image dans le format propriétaire du logiciel et dans un format ouvert PNG, JPG en fonction du type d'image.
Détourer un objet d'une image revient à enlever ce qui l'entoure. Il est erroné de penser que cette action ne s'effectue qu'au moyen d'un outil exigeant beaucoup de temps (et de patience). En effet, les logiciels de traitement d'images disposent d'outils très efficaces.
Dès lors, pourquoi se compliquer la vie ? Faites simplement le choix le plus pertinent selon le cas à traiter…
Cas 1 : un serpent à la peau lisse.
Cas 2 : un petit chien couvert de poils.
Enregistrez l'image dans le format propriétaire du logiciel et dans un format ouvert.
Intention généraleconnaitre les types de compression et les utiliser à propos
Pour qu'une image soit transportable, son poids doit être réduit. Différentes techniques plus efficaces les unes que les autres existent.
Bon nombre d’informations numériques transitent via l’Internet comme par exemple les images des pages web.
Les technologies de l’internet et du web sont très dépendantes de la vitesse de transfert de ces informations. Cette vitesse dépend de ce qu’on appelle la bande passante. C’est un peu comme sur les autoroutes : plus il y a de bandes de circulation et plus le trafic est fluide, ce qui, malheureusement, n’empêche pas les bouchons à l’occasion.
Vous savez que les images peuvent rapidement devenir lourdes et qu’une diminution de leur taille a des conséquences en termes de qualité et peu d’impact sur leur poids.
Que faire dès lors ?
Ce chapitre est consacré à la compression des images qui a pour but de les rendre plus aisément transportables et plus faciles à stocker.
Les techniques de compression sont nombreuses et variées car leur utilisation dépend un peu du contexte. Vous allez découvrir les effets de cette compression en termes de gain de poids, mais aussi en termes d’altération possible des images.
4. Des images qui s'emballent
Mise en situation
Vous souvenez-vous du panneau de signalisation (voie sans issue) que vous avez « décodé » dans une des activités du premier chapitre ? Revoici la grille qui peut être lue comme une longue suite de 225 chiffres (des 3, des 6 et des 9).
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
9
9
9
9
3
3
3
3
3
3
3
3
9
6
6
6
6
6
9
3
3
3
3
3
3
3
3
9
6
6
6
6
6
9
3
3
3
3
3
3
3
3
9
6
6
6
6
6
9
3
3
3
3
3
3
3
3
9
9
9
9
9
9
9
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
9
9
9
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
Pouvez-vous imaginer une manière de coder l'image qui soit plus courte, autrement dit qui utilise moins de 225 chiffres comme ci-dessus ? Quelles en seraient les conventions pour pouvoir à nouveau redévelopper la séquence initiale ?
Une solution pourrait consister à donner une valeur (un chiffre) et le nombre de pixels consécutifs auxquels elle s'applique (deux chiffres), puis la valeur suivante, et ainsi de suite. Dans ce cas précis, cela donnerait
319907308901...903312903321
Bien entendu, ce système ne fonctionne que s'il n'y a pas plus de 99 pixels consécutifs ayant la même couleur. Sinon, il faut passer à trois chiffres ou plus.
Avez-vous le courage de coder la suite entière jusqu'au bout en utilisant cette technique ? Si oui, quelle est la longueur de la nouvelle suite obtenue ? Et quel est le taux de compression ?
Le rapport est de 99/225 = 0,44 et donc, le taux de compression est de 56%.
Observons certaines choses. Par exemple, dans cette nouvelle suite, des séquences se répètent encore comme 312903.
Autre constat, la séquence 901 était représentée par le seul chiffre 9 dans la version non compressée.
Analysons un peu cet exemple.
4. Des images qui s'emballent
Réflexions
Compresser, c'est gagner de la place, c'est remplacer une suite de chiffres par une autre plus courte. Pour arriver à cela, les programmes de compression se basent sur des manières de procéder que l'on appelle des algorithmes.
Ces algorithmes sont généralement plus complexes que celui que nous avons décrit. On peut le deviner en constatant que, dans notre exemple, la solution contient de nouvelles suites de chiffres qui se répètent, ce qui pourrait nous encourager à imaginer une technique plus élaborée permettant une compression encore plus importante.
Nous avons également observé que lorsque les séquences de chiffres identiques sont courtes, on ne fait pas beaucoup de bénéfice. Cela signifie que toutes les méthodes ne conviennent pas dans tous les cas.
Pour laquelle de ces deux images notre méthode élémentaire s'avèrerait-elle la plus efficace ? Et pourquoi ?
Le taux de compression sera nettement plus important pour la première image évidemment. Les couleurs y sont moins nombreuses et surtout, de nombreux pixels voisins ont la même couleur. La méthode n'est pas du tout adaptée pour la seconde image dans laquelle les transitions sont fréquentes
Ce simple exercice nous suffit à distinguer deux grandes techniques de compression. Celles qui sont utilisées pour des images simples, de petite taille, comprenant généralement peu de couleurs et celles qui sont utilisées pour des images naturelles (photographies), qui contiennent de nombreuses couleurs et que l'on souhaite conserver dans une taille suffisante.
La compression sans perte
Lorsque vous achetez un meuble à monter, il est généralement emballé de manière telle que vous puissiez le transporter facilement. Son volume est réduit. Il en va de même pour la compression des fichiers et des images en particulier.
Notez que le principe de la compression n'est lié qu'aux problèmes de transport et de stockage. Cela veut dire que pour être traitée en mémoire centrale, en vue d'être affichée ou imprimée, une image doit être décompressée. « Sans perte » signifie que l'image avant la compression et après la décompression est rigoureusement la même.
Il existe deux formats de compression d'images sans perte très courants sur le Web. Les connaissez-vous ?
Le format GIF est un de ceux-là. Sa limite principale est de ne pouvoir coder les images qu'en 256 couleurs. Il est donc réservé à des images contenant peu de couleurs et d'une taille plutôt petite ne permettant pas de distinguer trop de nuances. Pour cette raison, il se raréfie.
Il est aujourd'hui supplanté par le format PNG. La technique de compression développée en PNG est plus efficace que la compression GIF. De plus, PNG accepte le codage des images matricielles en 24 bits et même au-delà. C'est ce qui explique son succès.
Les codages GIF et PNG n'utilisent pas les mêmes algorithmes. Toutefois, ces algorithmes s'inspirent de la technique élémentaire de codage que nous avons proposée dans la mise en situation.
La compression avec perte
Commençons par une question.
Connaissez-vous un type d'images auquel les formats précédents conviennent moins ou pas du tout ?
La photographie d'un paysage, par exemple, et donc les images naturelles s'accommodent mal de ces techniques car elles sont trop riches en nuances. Le format PNG pourrait à la limite convenir pour de petites photos dont on peut se servir comme vignettes ou comme icônes dans une page Web, mais certainement pas aux photographies de dimensions normales.
Pour ces images et spécialement pour elles, des experts ont défini un format particulier. Le principe est très différent du précédent. Il est basé sur des considérations physiques (perception humaine des fréquences lumineuses) et mathématiques (algorithmes complexes). Cela consiste, une fois le codage effectué, à effectuer une approximation sur le résultat. Cette approximation a pour conséquence de réduire le poids du fichier de manière intéressante (de l'ordre d'un facteur 10). Lorsque l'image est décompressée, elle est pratiquement semblable au niveau de sa perception car les différences sont indétectables.
Il s'agit du format JPEG. Son nom est l'abréviation de Joint Photographic Experts Group, ce qui montre que ce format a été conçu spécifiquement pour des images du type photo.
On parle de compression avec perte parce que l'image n'est plus exactement la même que l'image de départ. Mais perte ne signifie pas nécessairement perte observable de qualité. En revanche, l'approximation dont nous avons parlé peut être plus ou moins importante. Cela signifie qu'on peut obtenir des taux de compression plus ou moins importants. Si le taux de compression choisi est important, une légère dégradation de l'image est possible.
Observez cette photo prise dans la ville de Colmar. Ceci est une réduction. La définition de l'original est de 2592 pixels sur 1944. Le poids du fichier est de 14,4 Mo.
Compressée pour obtenir un maximum de qualité, elle pèse 2,4 Mo. Compressée pour obtenir un minimum de qualité, elle pèse 279 Ko.
Observons maintenant, en taille réelle, les détails d'une partie de l'image : le sommet de la maison située au centre. Observez les différences.
Détails de l'image peu compressée
Détails de l'image très compressée
Prenons un autre exemple, et donc une autre image. Nous choisissons un taux de compression minimum. Observez le poids annoncé du fichier.
Si nous décidons de choisir un taux de compression moyen, voyez comment le poids évolue.
L'évolution du poids n'est pas linéaire. Il faut donc trouver le bon compromis et faire en sorte que la qualité de l'image ne diminue pas.
4. Des images qui s'emballent
Activité
Mettons la (com)pression !
La compression de deux images d'aspect différent mais de dimensions identiques donnera-t-elle pour résultat des poids de fichier identiques ?
Objectif choisir un format optimal de compression des images
Dans le contexte de l'Internet, et particulièrement du Web, la problématique de la vitesse de transfert des images et de leur stockage sur des serveurs est cruciale. La compression est une solution efficace à cette problématique parce qu'elle contribue significativement à la diminution du poids des images.
Avec ou sans perte
Il existe différentes méthodes de compression. Certaines méthodes sont dites « sans perte » et d'autres « avec perte ». Perte ne signifie pas nécessairement perte de qualité, mais altération de l'image initiale. En d'autres termes, certains pixels vont (légèrement) changer de couleur.
Taux de compression
Dans une compression avec perte, le taux de compression aura une influence sur la qualité de l'image. Le choix de ce dosage permet de trouver un compromis entre diminution du poids et de qualité de l'image.
Dans une compression sans perte, il n'est pas question de qualité, mais de complexité de l'algorithme de compression/décompression. Une compression importante peut engendrer un délai plus important dans la reconstitution de l'image. On la réserve à des images de petite taille (de peu de pixels).
Formats d'images
BMP est un format non compressé et donc peu transportable.
GIF et PNG sont des formats compressés sans perte. Ils sont très efficaces pour la compression d'images peu nuancées comme des logos, des copies d'écran,... Le format GIF disparaît progressivement du Web car il ne convient pas aux images en vraies couleurs.
JPEG est un format compressé avec pertes. Il est particulièrement adapté pour les images naturelles (photographies).
4. Des images qui s'emballent
Exercice
Vous pouvez obtenir le corrigé de cet exercice auprès de votre coach.
Faire le bon choix
Voici plusieurs affirmations.
Sont-elles vraies ou fausses ? Complétez le tableau.
Affirmation
Vrai
Faux
Les images au format BMP ne sont pas compressées.
La compression permet de gagner de la place en mémoire vive.
La compression permet de gagner du temps dans le transfert des images par Internet.
La compression au format PNG est une compression avec perte.
Les images au format GIF sont des images en « vraies couleurs ».
La compression au format JPG est une compression avec perte.
Le format PNG permet de fixer un taux de compression.
Le format JPG permet de fixer un taux de compression.
Le format JPG est adéquat pour des images qui contiennent peu de couleurs.
Un appareil photo numérique ne produit que des images non compressées.
Certification
Le traitement de l'image
L'épreuve de certification comprendra des activités et des exercices semblables à ceux du chapitre. Si vous pouvez les refaire, vous êtes paré(e).
La certification comprendra aussi une partie réflexion sous forme d'un QCM. Le test que vous pouvez télécharger ci-dessous vous permet de vous en faire une idée précise.
Pour la correction des exercices et du test, adressez-vous à votre coach.

















































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}